La recente decisione dell’Alta Corte britannica nel caso Getty Images contro Stability AI non è solo un fatto di cronaca legale internazionale, ma un fondamentale campanello d’allarme per tutte le società di sviluppo AI in Italia. La sentenza, che ha visto Getty uscire in gran parte sconfitta, sposta il focus legale dall’addestramento (training) all’output finale.
Il principio chiave: apprendimento vs. copia
La tesi centrale che ha prevalso in questa storica controversia è chiara e si allinea con l’evoluzione del dibattito legale internazionale: i modelli di AI apprendono dai dati, non li memorizzano né li riproducono.
Come brillantemente sostenuto da James Cameron, l’attenzione legale non dovrebbe concentrarsi sul processo di addestramento (training-as-copying), ma sull’output finale generato dall’utente.
“Il mio output… dovrebbe essere giudicato sulla base della sua eccessiva vicinanza, o plagio.”
L’Alta Corte britannica ha sostanzialmente recepito questo principio, dichiarando che Stable Diffusion (il modello di Stability AI) “non archivia né riproduce alcuna opera protetta da copyright.” Questo sposta l’asse del controllo legale: l’infrazione del Diritto d’Autore avviene solo se l’immagine prodotta dall’utente è sufficientemente simile a un’opera esistente e protetta.
Implicazioni giuridiche e movimenti di mercato
La sentenza britannica, pur non essendo direttamente vincolante in Italia o nell’Unione Europea, rappresenta un importante precedente giurisprudenziale che influenzerà inevitabilmente i futuri dibattiti in merito all’applicazione dell’attuale normativa (in particolare la Direttiva sul Diritto d’Autore nel Mercato Unico Digitale, CDSM Directive) e le discussioni sull’AI Act.
Mentre i tribunali procedono con cautela e con tempistiche estese, il mercato si sta già muovendo rapidamente:
- Dalla querela alla licenza: grandi player del settore, come l’industria musicale (es. l’accordo tra UMG e Udio), stanno abbandonando le lunghe cause legali per adottare modelli di licenza per l’utilizzo dei contenuti nel training AI.
- L’Oofferta dei querelanti: gli stessi plaintiffs storici, come Getty Images, stanno lanciando i propri tool di generazione AI che promettono contenuti “commercialmente sicuri” e indennizzati (come Firefly o i generatori basati su licenze Shutterstock).
Questo dimostra che, indipendentemente dalla velocità dei tribunali, l’industria sta puntando su soluzioni legali e contrattuali per gestire il rischio.
Le contromisure legali per le aziende Tech
L’approccio del “aspetta e vedi” è ormai obsoleto e pericoloso. Le aziende che sviluppano o utilizzano sistemi AI devono agire ora per garantire la conformità e la tutela della propria Proprietà Intellettuale.
Cosa fare subito:
- Implementare stack coperto da licenza e legalmente garantito: scegliere piattaforme AI che offrono termini aziendali chiari e, soprattutto, indennizzo contro eventuali future rivendicazioni di Diritto d’Autore (es. Firefly, Copilot Enterprise, etc.).
- Tracciabilità e trasparenza (C2PA): abilitare le credenziali di contenuto C2PA (Coalition for Content Provenance and Authenticity) per la tracciabilità dei contenuti generati, e registrare sistematicamente i prompt e gli output per scopi di audit legale.
- Revisione legale preventiva: integrare una revisione legale obbligatoria pre-rilascio per tutti gli asset generati dall’AI destinati all’uso commerciale.
In conclusione: la sentenza Getty v. Stability AI non chiude la questione, ma ne delimita il campo d’azione. Il rischio legale non si annulla, ma si sposta dalla fase di addestramento alla fase di utilizzo del risultato. È imperativo per gli operatori del settore non attendere la perfezione normativa, ma adeguarsi alle soluzioni che il mercato, e ora la giurisprudenza, stanno delineando.
Cosa significa per le aziende Italiane?
La tesi vincente, sostenuta anche da James Cameron (membro del consiglio di Stability AI), è ormai consolidata: i modelli di AI apprendono dai dati, non li copiano. Di conseguenza, l’infrazione del Diritto d’Autore avviene solo se il contenuto generato dall’utente è considerato plagio.
Questo contesto, apparentemente lontano, ha implicazioni immediate per la legge italiana e la futura compliance.
La pressione Europea: AI Act e l’obbligo di adeguamento
Mentre la giurisprudenza UK definisce il confine tra apprendimento e copia, la legislazione comunitaria impone nuove regole che le aziende italiane devono affrontare subito:
- L’AI Act: il futuro Regolamento Europeo sull’Intelligenza Artificiale mira a classificare i sistemi in base al rischio, imponendo obblighi stringenti (documentazione, trasparenza, human oversight) sui modelli “ad alto rischio”. Le aziende italiane che sviluppano o utilizzano questi sistemi devono pianificare la Compliance-by-Design ora, non dopo l’entrata in vigore del Regolamento.
- Diritto d’autore e testo & data mining (TDM): la Direttiva Europea sul Diritto d’Autore (CDSM Directive), recepita in Italia, prevede eccezioni per il TDM (l’estrazione di testo e dati a fini scientifici o commerciali). Tuttavia, per l’uso commerciale (il training dei modelli AI), l’estensione dell’eccezione può essere limitata dai titolari dei diritti (il cosiddetto opt-out). La corretta gestione di queste eccezioni e delle relative licenze è un rischio legale critico in Italia.
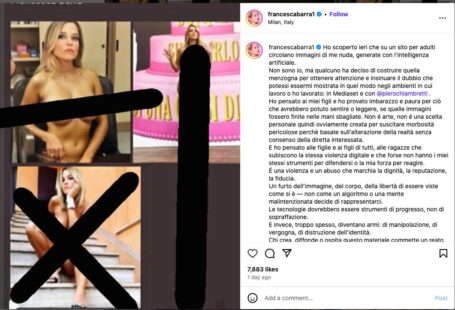
- GDPR e dati biometrici: i modelli di AI che elaborano dati personali, inclusi dati biometrici o sensibili, devono garantire la liceità e la minimizzazione del trattamento, in perfetta conformità con il GDPR.
Affrontare queste normative non è un’opzione, ma un imperativo strategico che definisce la sostenibilità e la bancabilità di qualsiasi azienda AI.
Non aspettate la legge: l’errore costoso di molte aziende
Molte tech company italiane credono ancora che sia sufficiente “aspettare l’entrata in vigore dell’AI Act”. Questo approccio è estremamente rischioso:
- Rischio contenzioso TDM: senza un’analisi legale preventiva sul data set, si è esposti a richieste di risarcimento per violazione del Diritto d’Autore da parte dei titolari che hanno esercitato l’opt-out per il TDM.
- Perdita di competitività: il mercato si sta già muovendo verso soluzioni licenziate e indennizzate. Non adeguarsi significa perdere l’accesso a partner internazionali e a venture capitalist che esigono una due diligence legale impeccabile.
La soluzione legale strategica: Dandi Media, esperti in Legge AI
Per le società italiane che sviluppano o utilizzano l’Intelligenza Artificiale, la conformità e la tutela dell’IP non possono essere affidate a consulenze generiche.
Dandi Media è lo studio legale specializzato che offre la competenza esatta di cui avete bisogno:
- Analisi di Data Set e TDM: valutiamo la conformità legale dei data set utilizzati per il training AI, minimizzando il rischio di contenzioso per Diritto d’Autore (gestione dell’opt-out TDM).
- Preparazione AI Act: affianchiamo la Vostra azienda nella classificazione del rischio dei modelli e nella strutturazione della documentazione tecnica e legale necessaria a soddisfare i requisiti del Regolamento (es. GDPR e AI Act in sinergia).
- Tutela IP del Vostro Modello: garantiamo la protezione legale del Vostro core business – dal know-how (segreti industriali) alla tutela dei diritti sull’output generato.
Non è il momento di aspettare. È il momento di blindare il Vostro business.
Affidate la gestione del rischio legale a chi conosce il Diritto d’Autore e il Diritto dell’AI.
Contattate oggi lo studio Dandi Media per una consulenza strategica sulla compliance del Vostro sistema AI
Lo Studio Legale Dandi fornisce assistenza legale in diverse aree di competenza. Dai un'occhiata ai nostri servizi oppure contattaci!